HPC Batch Executor
Documentation and best practices for using the HPC focused batch executors. These new executor types support key scheduling systems including; Cobalt, LFS, and Slurm. Learn how to use this tool in your GitLab CI workflows targeting facility resources.
Batch Executors
If you’ve worked with the GitLab Runner before, you may be familiar with the concept of an executor. Each type of executor allows for CI jobs to run using different mechanisms but with the same script. For example, the simplest is shell. This runs jobs locally by spawning a new shell (e.g. Bash). In order to better support the range of required CI workflows on facility hardware and ease interaction with the HPC schedulers, the batch executors had been introduced.
Each type of batch executor runs user defined CI build script
(combination of before_script & script) by submitting it
to the underlying scheduler. Meaning each CI job equates to a single
submission to the scheduling system.
As of the latest release, we only support Cobalt (qsub), Slurm (sbatch), and LFS (bsub). There is no common language between schedulers and you will be required to account for these, as well as differences in facility environments, when you structure your job. However, to support this you can directly influencing job submission using Scheduler Parameters, the same way you would on the command line.
Looking at a quick example job we can observe how the
contents of the .gitlab-ci.yml file result in
a job submitted to an example Slurm scheduler.
example-batch:
variables:
SCHEDULER_PARAMETERS: "--nodes=2 --partitions=power9"
script:
- hostname
- echo "${SLURM_NODELIST}"
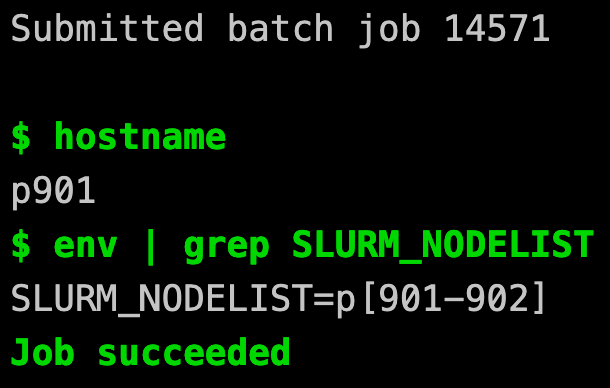
Comparing the defined job to the results found in the log below, you
can directly observe both how the resources request was affected
and the script executed. With the SCHEDULER_PARAMETERS we
requested two nodes on a power9 partition. Then our script
is executed on the resources that meet what had been requested.
Scheduler Behavior
Each of the currently supported schedulers behave differently. It is important to recognize those difference when constructing your project’s CI jobs.
Cobalt: Qsub is invoked to submit a job to the queue. All commands are executed from the launch node and running on the compute resources requires a call to
aprun. The output and error log are both monitored to generate the CI job log.LSF: Bsub is used to submit the job to LSF. All commands in the script are executed on the login node and parallel run commands (e.g.
lrunorbrun) must be used to leverage compute resources. The job is submitted interactively (-I).Slurm: The sbatch program is used to submit the job script. This means all commands are executed directly on the compute resource. The output log is monitored for the purposed of providing the CI job log
If your unfamiliar with a scheduler or specific command we advise referring to the documented provided by the facility hosting the test resources.
Scheduler Parameters
By using CI/CD environment variables
we are able declare the resources/configuration a CI job requires.
By using the SCHEDULER_PARAMETERS key, the associated value will be
used in the request for an allocation. Let’s look at an example
for Slurm:
example: variables: SCHEDULER_PARAMETERS: "--nodes=1 --partition=ecp-x86_64" script: - make hello-slurm tags: [batch, slurm]
Since we’ve supplied
SCHEDULER_PARAMETERS: "--nodes=1 --partition=ecp-x86_64" that means
we are requesting a single node on the specified ecp-x86_64 partition.
If we were to manually request the same resource it would look like this:
sbatch --nodes=1 --partition=ecp-x86_64 gitlab-runner-script.bash
Note
Key elements of the underlying interactions with the scheduler have been documented for administrator purposes under Supported Executors. Though reviewing these is not required, the additional context may be of assistance for some.
Configurable Variable Key
Not all deployments will rely solely on the default SCHEDULER_PARAMETERS
key as runner admin can configure additional supported options. By allowing
for configurable options sites can look for distinct keys. This can
facilitate defining pipeline wide behavior that then will only be observed
by the appropriate runner:
variables: SITE_A_SLURM_PARAMETERS: "-N2 -n 4 -p x86" SITE_B_COBALT_PARAMETERS: "-A account -n 1 -q debug" example-job: ...
Missing or incorrectly specifying the variable will cause a warning message but will not stop the job from running:

Conflicting Parameters
Due to the structure of the runner and how jobs are submitted to the underlying schedulers we enforce some default behaviors. In order to ensure jobs operate as intended there are several parameters that conflict with system behaviours and must be observed:
Cobalt:
-o, --output, -e, --error, --debuglogFlux:
--job-name, --output, --errorLSF:
-o, --output, -e, --error, -eo, -ISlurm:
-o, --output, -e, --error, -J, --job-name, --wait
Use of any of these parameters will result in job failure.
Compute Resources
Not all aspects of a CI job are executed using the compute resource as GitLab splits a job into multiple stages, each of which are executed with a new runner generated script. For example, using Git to obtain the source file is its own stage, as is upload/downloading artifacts. All of these runner managed stages are executed outside of an allocation and will never be submitted to a scheduler.
There are then two remaining stages that are directly controlled by script defined in your job. First is the build_stage which is a concatenation of anything defined in the before_script and main script. This is the only stage is submitted to the scheduler. The after_script is executed separately and in a completely new environment. For a more detailed look at where user defined scripts are executed please reference the below table.
Cobalt |
Flux |
LSF |
Slurm |
|||||
|---|---|---|---|---|---|---|---|---|
Script Elements |
Location script will run? |
qrun? |
Location script will be run? |
flux alloc? |
Location script will run? |
brun? |
Location script will run? |
srun? |
before_script |
launch/mom node |
yes |
batch node |
yes |
launch node |
yes |
batch node |
yes |
script |
launch/mom node |
yes |
batch node |
yes |
launch node |
yes |
batch node |
yes |
after script |
login node |
no |
login node |
no |
login node |
no |
login node |
no |
Allocations
Your project’s allocation can be used when leveraging the batch executor. The specific facility rules are determined on a site-by-site basis and for details you should consult the associated facility contact. However, if we assume that running CI can be counted, what should you do to minimize this cost?
The first and easiest step you should take is determining when in your CI workflow you should use a batch executor. Understanding the target environment and attempting to use available builds resources such as a shell runner or in some cases a build farm can minimize time spent compiling both your software as well as dependencies. You can also move more expensive, multi-node or long run production tests further into the CI pipeline. Thus ensuring smaller runs tests and builds complete successfully before longer run tests are submitted.
Inadvertently using hours from your allocation for unnecessary CI jobs is avoidable. There are tools within GitLab that you can use when configuring your pipeline to restrict when jobs can run. The strongest recommendation we can make is making use of the rules keyword. There is also a flag, interruptible, that can be enabled to allow for the cancellation of jobs if they become redundant by newer pipelines.
The final recommendation is to rely on the scheduler to enforce time limits, not on GitLab. As highlighted in the Job Timeout section, there is a disconnect between GitLab’s timeout and that of the underlying scheduling system. When defining your Scheduler parameters it is highly recommend you specify a wallclock to avoid problem jobs running longer than expected.
Taking steps with how you structure your project’s configuration along with prioritizing test resources for approved efforts can go a long ways to ensuring your available allocation provides the most value.
Interactions with Default GitLab Behavior
Though we’ve taken steps to ensure that default GitLab functionality will work as officially documented with the batch executor, in some cases issues cannot be completely avoided. As these are identified we will document them and attempt to provide workarounds that you can choose to leverage in your project.
Job Timeout
GitLab offers several ways you can manage the default timeout for jobs. A runner administrator can manage it on the runner level, project maintainers can define a project level, and as of GitLab version 12.3 it can be configured on the job level. All these configuration can provide a lot of value to you project’s CI deployments. However, with the batch executor you know not only can manage a wallclock with the underlying scheduler but have the added complexity of unknown queue times.
At this time it is important to note that the GitLab runner has no concept of the underlying queue. As such, any GitLab enforced timeout will continue regardless if a job is simply waiting in queue or running. We recommend that you greatly increase your project-level timeout (expected time in queue plus time for job execution) and rely on the schedulers wallclock to enforce job level timeouts.
Available Scheduler
When examining runners under a project’s settings (found under Settings -> CI/CD -> Runners) you will not find any specific details regarding the scheduler or batch specific configuration associated with the runner. At this time we rely on well formed runner tags established by the admin and have expanded the information/warring messages generated by the runners to provide missing details.
Capturing CI Results
As with all other GitLab executors, stdout/stderr produced by your CI job will be transmitted, along with any artifacts, back to the GitLab server. Your team may wish to leverage additional workflows with how these results are managed.
Note
You are responsible for adhering to any and all facility policy when managing CI results!
GitLab API
GitLab offers a robust Jobs API that can be used to obtain artifacts as well as log files. Using this endpoint can be done from any resource with HTTPS access to the GitLab server and outside of the duration of your CI job. Results obtained through the API are the same as you would gather by manually traversing the web interface.
Uploading Results to a Third-Party Dashboard
Warning
Enforcing masking CI variables is done by the GitLab Runner and will not be reflected in any third-party dashboard. We advise you carefully review the expected contents of any upload to avoid exposing sensitive information.
Since ultimately the script generated is simply Bash and executed under your local account, it is possible to run any script/command you may normally run to upload results to a separate dashboard (e.g. CDash). Since the results may be generated on a compute resource, which traditionally does not have internet access, we advise using such commands in the after_script. As highlighted in the Compute Resources section, all after_script commands will be executed on the launch/login node.
Copying Logs
Select schedulers (Cobalt & Slurm) generate job logs as part of the CI
process which are in turn monitored by the runner. This monitoring
process feeds the contents of these log files back the GitLab web.
By default these logs are removed upon completion of the scheduled job
by the runner; however, it is possible retain a copy of these for your
records. By defining the COPY_SCHEDULER_LOGS using GitLab variables.
example-job:
variables:
COPY_SCHEDULER_LOGS: "/scratch/myLogs"
The copy will only occur upon completion of the scheduled job, regardless of the job’s final exit status.
$ ls -l
-rw-rw-r-- 1 user user 252 Dec 12 10:09 slurm-out-8870.log
Note
All interactions are executed under the validated CI user, as such local file permissions will be observed.
A GitLab variable can refer to other variables, for instance
using $HOME/logs as a value, GitLab would try to resolve $HOME to
a CI defined variable of the same key. Instead using the $$HOME/logs
to escape and allow the value to be resolved by Bash as expected.